解析:大数据的滥用及弱点
大数据这个话题在网上传的很神,尤其是我国这个每个人什么都懂一点但又懂得不精的土地上,有种安利好产品准备取代传统营销的感觉。
对码农来说如获至宝,世界上的数据太多,本来被认为是煤干渣的东西现在好像也可以当钻石了,煤窑工人挥舞锄头高喊:万岁data mining!不过我认为这也没错,随着技术的进步,苞米也能替代汽油,煤干渣也可以做成首饰。大数据对工程学是很好的,但是矿工拿煤干渣当钻石推销到社会科学,说这玩意可以代替统计学和抽样技术,我就不乐意了。物理学家对大数据也颇有微词,不过我不懂物理就不说了。

国外对大数据在其他领域滥用已经有了很多批评,我总结一下主要:
1,无意义的显著性:没有理论的大数据是皮毛,只看到显著相关性,但不经检验,没有理论,这样的相关是没有意义的,或许是虚假。关键是:大数据的data point太多,在计算上找到两个矢量的显著关系极其容易,但正是因为数据量大,控制虚假关系反而更难,这是一个两难。我有一篇文章投出去,匿名评审说:样本很大,当然能找到显著相关,但是看不出意义。
2,采样方法问题:统计学家方凯撒总结了一个现象,谷歌、facebook等网络收集的数据,往往不具有同质性,是在不同的时间用不同的资源收集,随后把整个数据合并起来,结果大数据内部许多部分的数据根本不是用同样的方法收集的,统计抽样的基本假设都被推翻了。而且网络数据和线下数据的内容不一致,比如华尔街邮报的电子版和纸版就不一样,而且用户可以自定义内容。
3,机器语言不稳定:谷歌最开始用关键字预测感冒流行地区,开始说比疾控中心预测的还准,但后来越来越不准。有人认为这是谷歌的搜索算法在不停地改进,所以自动收集数据不稳定了。另外机器语言一旦被误导会越错越离谱,比如谷歌翻译是根据真实的文章总结的,但是有些网络的“真实”翻译其实是谷歌翻的,于是谷歌会把自己的翻译基于这些 “真实”文章上。
以上归根结底是人和机器的矛盾:数据必须让人用理论来指导、收集,否则会出现谬误。这些都是可以避免或改进的,但这些原因足以让大数据在短期之内难以在社会科学领域立足。除此之外,我自己有一个想法,基于一个假设,认为大数据是不可能在人类行为领域立足的,研究文本或死物的历史学、语言学或许可以,但是社会学、犯罪学、人类学这三个恐怕很难。
学抽样的都明白,只要确定了图1中想要的准确度 Z(a/2)^2,方差S,回答率r,基本就可以求出从一个人群中应该抽多少个样本才能有代表性,而人群总量N的影响最后就不大了。在95%置信区间的情况下,一个小镇4000人,一个城市十万人,从小镇抽360人可以达到代表性,从那个城市抽390人照样可以有代表性,不可能因为后者多了几百倍就要多抽几百倍的人。所以大数据首先就没有必要了,在满足准确性的时候,小样本和大数据的效果没有区别;而不满足准确性的时候,大数据的误差只会更大。
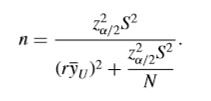
这只是最基本的情况,实际抽样中往往需要分层,二龙湖有十块苞米地,有些面积大有些小,有些里面有非法性交易,要找那块苞米地里有性交易,就得把十块苞米地分成两类:离人烟近的,离人烟远的,赋予后者的抽样概率要大。这是所谓分层抽样,现实中,几乎所有大规模抽样都是分层抽样的变种。
分层抽样的情况下,后期统计运算都必须一个权重w,如图2,每层人数M和n都暂时不重要,权重是和phi成反比的:phi是该层被选择的概率。一个分层的权重高,在分析中就不可忽视。大数据的问题是它只能收集到权重低的数据:
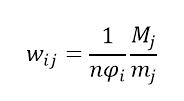
我们知道帕累托分布,应用很广,从小姐接客分布到富豪财产分布都可以用帕累托分布表示。另一种类似power distribution的Zipf曲线,P(r)=1/(r*Ln(R)),用来表示重要性和出现频率:语言学中,一个词日常使用频率与它的排名成反比,chinkafir这个词排第10000,它的出现概率就大概是1/10000。由于这个分布的广泛性,我有一个基于权重的假设:因为抽样概率越低的分层,的权重越高;所以越难被抽样的人群,的统计重要性越高。现实中,最容易研究的对象往往最无聊,心理学经常上课找大学生做实验,所以现在以大学生为样本的文章很难发表了;而谁要在二龙湖跟浩哥混几天,做出来的研究就算不很严密也依然重要。
这点才是我说大数据的第二个重要弱点,数据越大越不重要。一个人收集了一堆权重接近0的中产阶级对暴力犯罪的态度,而另一人在Cicero和Latin Kings混了两个月,你觉得谁的结论重要?不是说前者没有意义,普通人群在分析时是必要的,但大数据基本只能接触到一些数据,没有抽样技术的话永远不具有代表性。就跟安利一样,产品或许不错,但是推销方式往往太傻逼,想取代传统还需努力。
来源:网络大数据

未来的制造业要的不是石油,它最大的能源是数据.